在今天的Pandas學習筆記中,我們深入探討了數據處理的關鍵環節,重點包括數據重塑和軸向旋轉、數據分組及運算、離散化處理以及數據集合并。這些功能為高效處理和分析數據提供了強大支持。
一、數據重塑和軸向旋轉
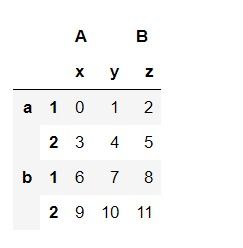
Pandas提供了靈活的數據重塑工具。stack()函數可將列索引轉換為行索引,實現數據的堆疊;而unstack()則執行相反操作,將行索引轉換為列索引。pivot()和melt()函數分別用于數據透視和逆透視,以適應不同的分析需求。軸向旋轉功能通過swaplevel()和reorder_levels()方法調整多層索引的順序,提升數據操作的靈活性。
二、數據分組和分組運算
使用groupby()方法可以根據指定鍵對數據進行分組,例如按類別或時間周期。分組后,可應用聚合函數(如sum()、mean()、count())進行統計分析,或使用transform()和apply()方法執行自定義運算。分組運算支持多級分組和條件篩選,便于從多維度洞察數據特征。
三、離散化處理
離散化將連續數據劃分為區間,常用于數據分箱或分類。cut()函數根據指定邊界將數值數據分段,而qcut()則基于分位數進行等頻分割。離散化后,數據可轉換為分類變量,便于進行分組統計或可視化,同時減少噪聲影響。
四、合并數據集
Pandas支持多種數據合并方式:concat()用于沿軸拼接多個DataFrame;merge()基于鍵值連接數據集,類似SQL的JOIN操作;join()則按索引合并。這些方法允許處理不同來源的數據,確保數據整合的準確性和效率。
通過掌握這些Pandas核心功能,我們可以更高效地清洗、轉換和分析數據,為后續建模和決策打下堅實基礎。實踐中需注意數據一致性和性能優化,以應對復雜業務場景。